Fixing Flaky Tests
- 11 min read
- Tests
- GitHub
- Python
- Open Source
3 years ago
Hello!! Long time no see. I recently did this project as part of the CS 527 (Topics in Software Engineering) course at the University of Illinois Urbana-Champaign . It was some super exciting stuff and I wanted to write about it here.
For Fall 2022, the course was taught by professor Darko Marinov . Super cool professor. Here's the course description:
Fault-tolerant software, software architecture, software patterns, multi-media software, and knowledge-based approaches to software engineering. Case studies.
Each year, the content of the course slightly changes. This year, the emphasis was on testing. One of the 3 routes students have the opportunity to take is fixing flaky tests. What are flaky tests, you ask? Well, in short: they're tests that fail on subsequent runs with no changes to the code or the test itself. Imagine that: You changed nothing. You didn't touch a thing. But you run the test a second time and it fails. Frustrating. This is just one example. There are many reasons why a test might be considered flaky. This paper has more information about the type of tests.
Other reasons why a set of tests might fail is when you run them in a different order than indended. One type is a victim, an order-dependent test that passes when run in isolation but fails when run with some other tests. The other type is a brittle, an order-dependent test that fails when run in isolation but passes when run with some other test / tests.
Students who picked this route were tasked with fixing flaky tests. Now, finding them is another aspect of the problem. You'd have scripts that run tests multiple times, such as pytest-flakefinder . Each time it runs, it checks to see if all the tests pass. If flakiness is present, the script tells us. Thankfully, there was already a list of tests that were detected. All I had to do was choose tests, recreate the flakiness, fix the tests, open PRs, and get them merged. But, there was another problem. A lot of the tests on the list of detected tests that were provided to us were old. Archived code. You'd be awarded 5 points for getting a PR accepted. But only 1 for opening them. Why would someone accept a PR on a repostiroy that was not being maintained? They had absolutely no reason to.
Often times, recreating the flakiness was the biggest problem. And then once that's done, you'd have to fix the actual issue. By the end, I fixed a total of 26 tests across 7 open-source repositories. After this, you had to convice the maintainer of the repository that the change you're suggesting is a good one that they'd actually consider. I couldn't go and just find a source of flakiness and fix it. I had to find out exactly why it occurred, find out how to fix it, and find out if the fix makes sense in context to the rest of the code. Because more often than not, the test you're modifying has ramifications on other tests. So you fix the flakiness in one, and another one appears. But wait, you finally fixed the flakiness. All tests pass! But wait, why did it work? How do I convice the maintainer of the repository to accept my pull requests?
So many things to juggle. One challenge after the other. It taught me a lot about overcoming challenges and sticking with something. Because the time spent on some tests were long. Way too long. With no fruitful outcome. And it sucks. But you learn.
Scripting!
The first PR I fixed was on the repository with the most amount of stars, and the one with the most recent commits. I had to write a script to get these repositories, because sifting through an excel sheet with 1000s of rows and checking each repository to see if it was maintained was tiring. Here's the script which scrapes an existing Excel sheet, notes down the number of stars and number of months since latest commit, and sorts in descending order of number of stars and ascending order of months since last commit. Both these pieces of information together in this specific order help to shortlist a repository to fix tests on. The higher it is on the list, the more chance your PR had of getting accepted.
Fixing the test
The repo at the top of the list was pingouin , an open-source Python package used for statistical analysis. Alright. First step is to recreate the flakiness. Easy enough. I ran all the tests once with pytest. They all pass. I then use the pytest-flakefinder plugin, and run the tests again. Remember, this plugin runs the tests multiple times, in different orders, and often without resetting certain state information. When this happened, only the first test passed. The rest of the tests failed:
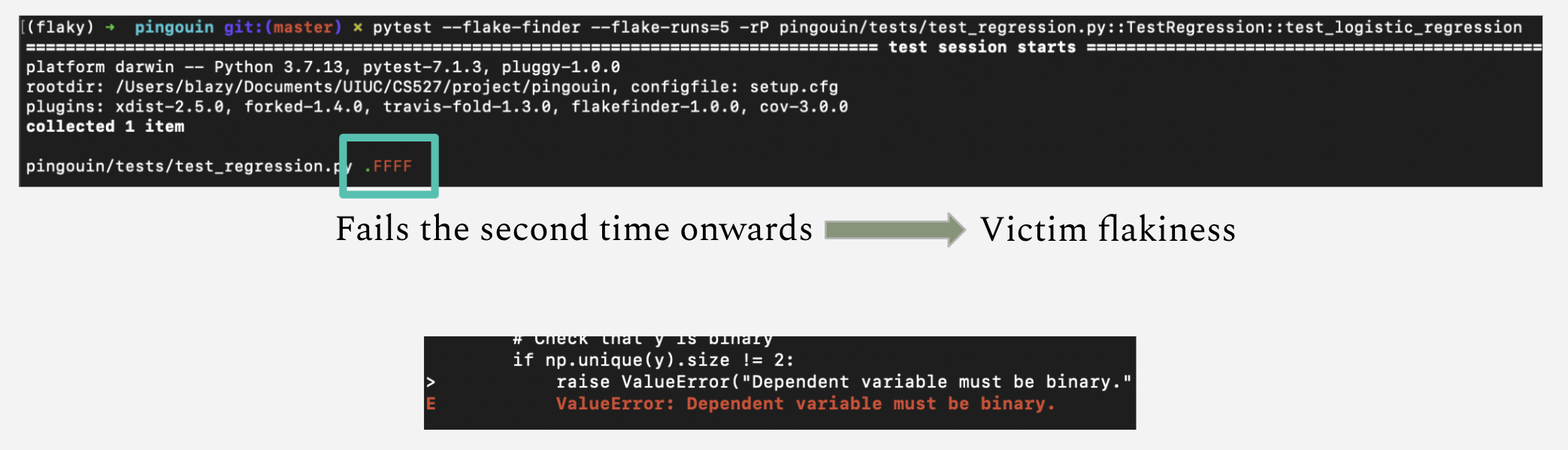
Great, now we have somewhere to start. The error message tells me exactly where the issue was occuring. So I go ahead and start debugging (with print statements, like a true programmer). Here's what was happening: after a DataFrame was initially read certain columns were not being added to the DataFrame in some tests, and without these columns, the test would fail. All I had to do to fix it was add 4 lines (2 to each test that was failing):
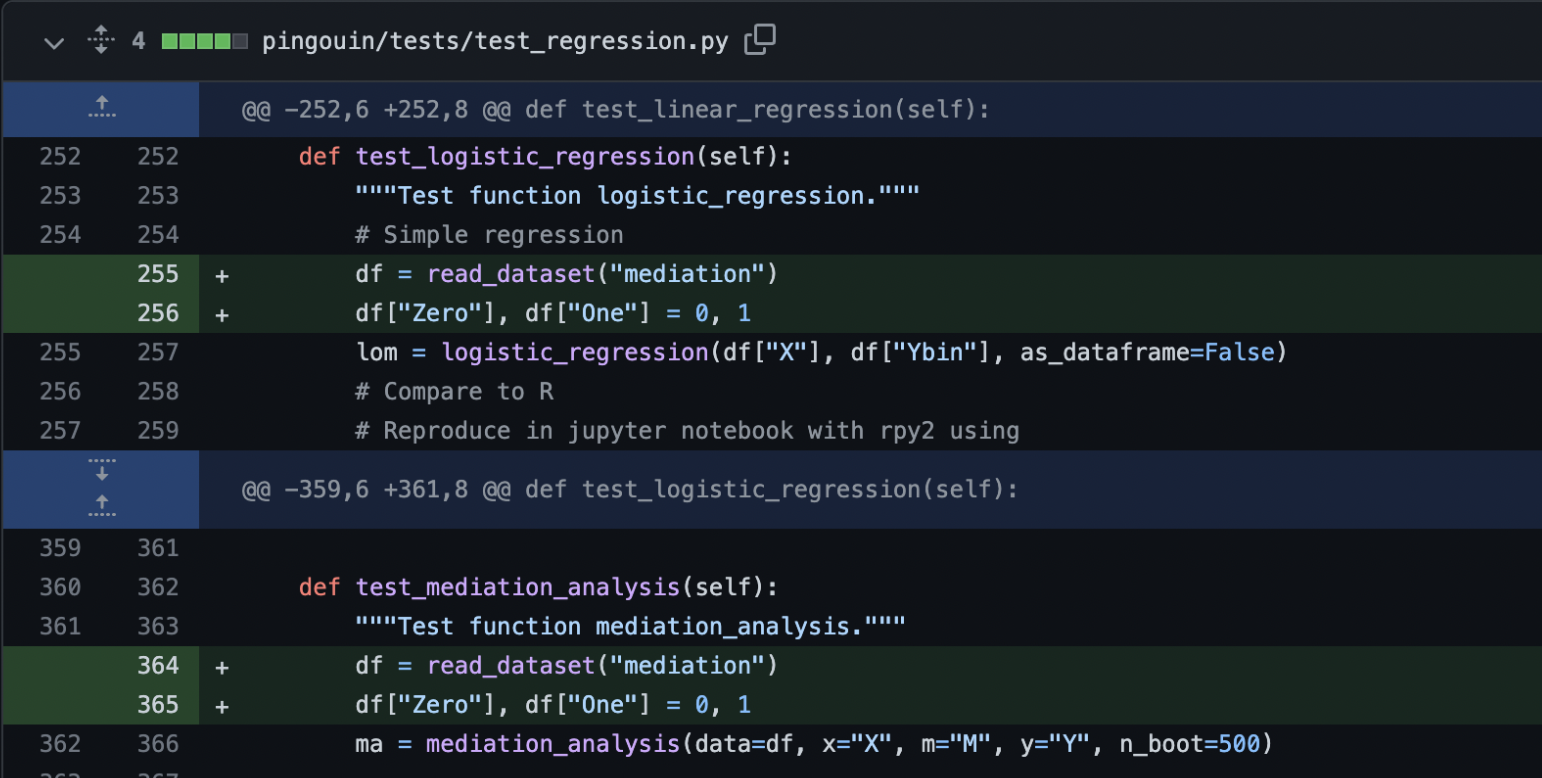
When re-running pytest-flakefinder, all the tests passed, which means the test was successfully fixed. Now, all that's left was to open a pull request.
Opening the PR
Certain points needed to be addressed if I were to convince the developer to merge my PR.
- Give context. Tell the repo maintainer what's happening, and why it is happening.
- Convice. The developer might be running his suite of tests once, and be happy that they all pass. After all, who wouldn't be? Most developers don't think about flaky tests, atleast on pretty small open source libraries. So I had to be mindful and explain how to replicate it, and why it would be a problem in the future (hint: flaky tests are notoriously hard to debug if not caught early on)
Hitting all these points on the PR, this was what I had:
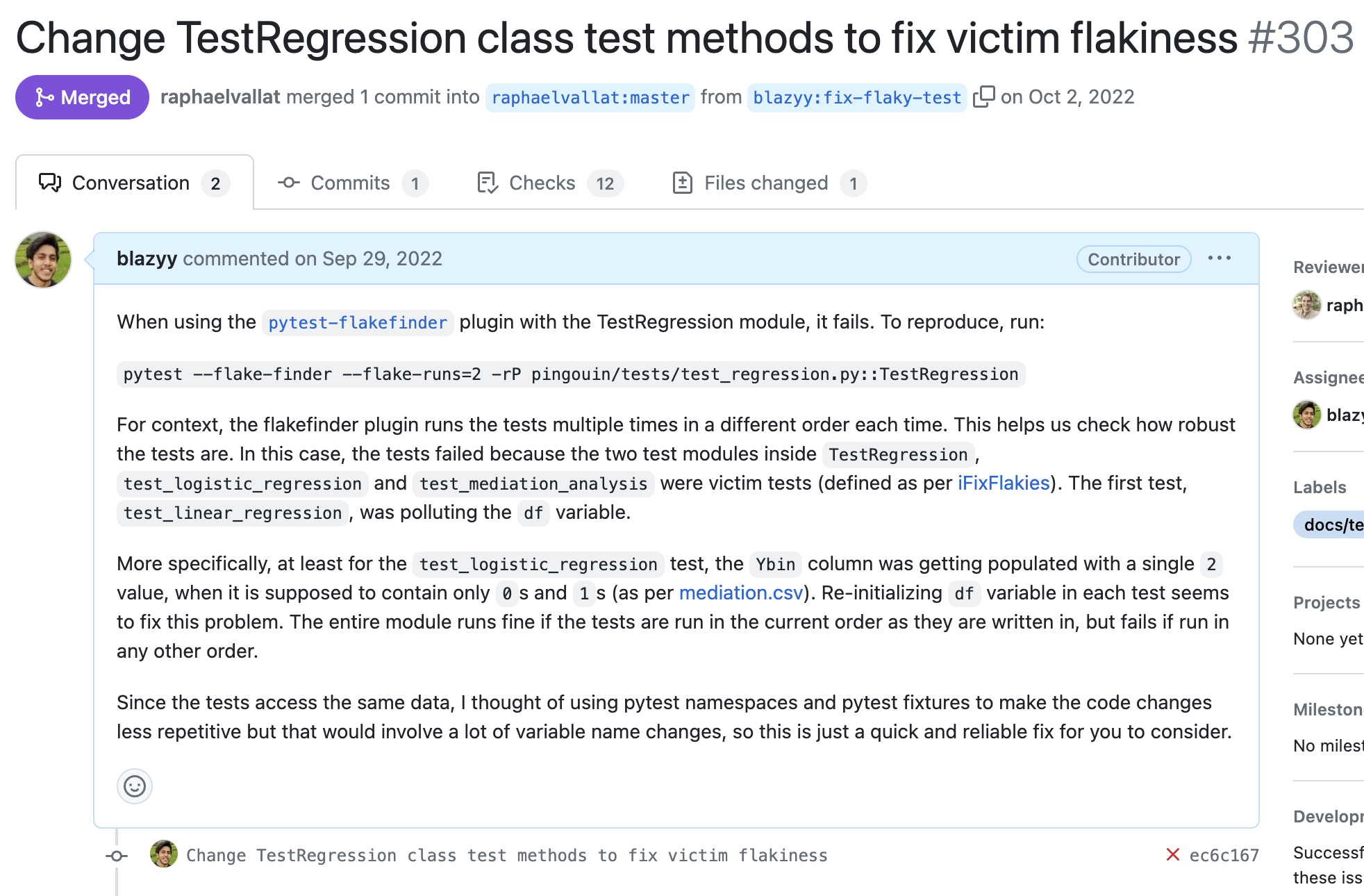
And after waiting a few days, the developer accepted my PR (yay!)
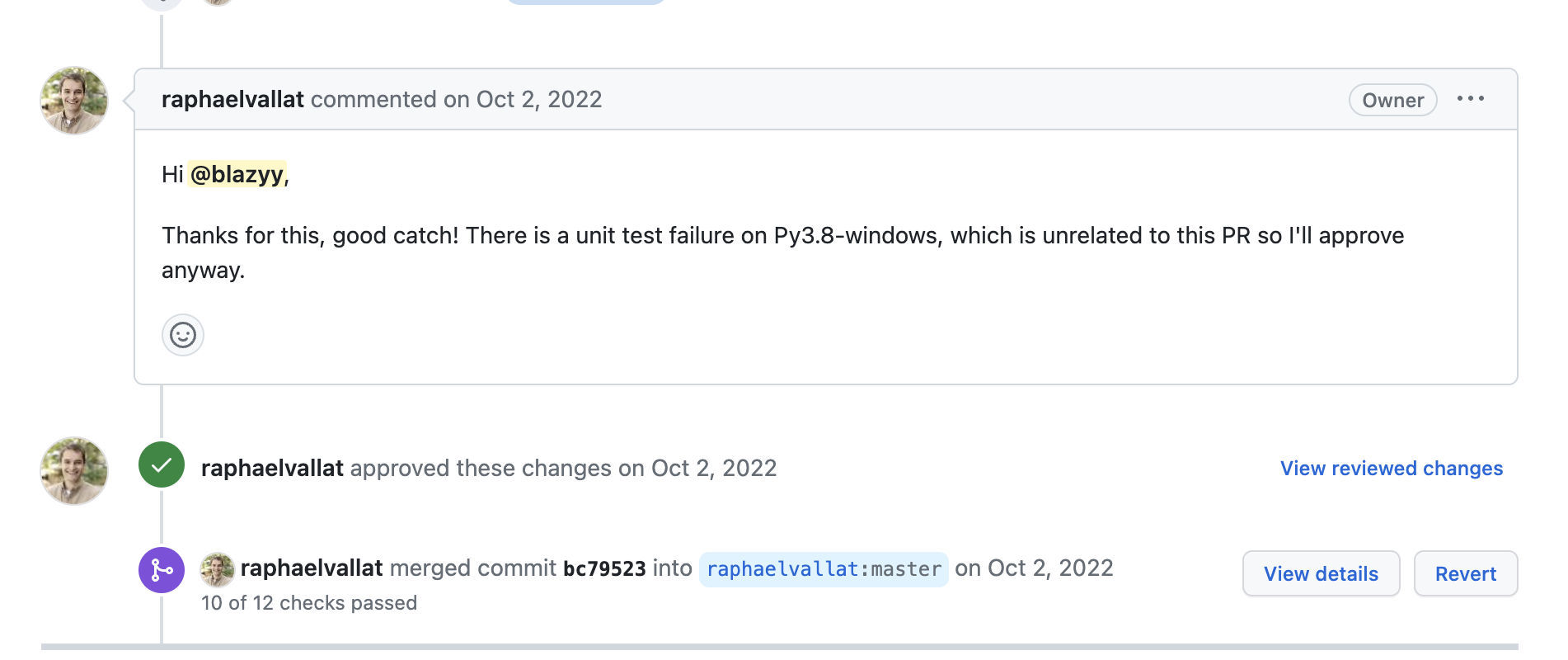
Okay. Great. One down. 5 points! I needed atleast a 100 to pass...
What after?
The rest the came after weren't as easy as the first one. There were a multitde of problem that came up, which I very graciously mentioned in my report, which was a part of the final submission for the class. By far, I have never learnt more from a class than before. Sure, almost all of this involves self-teaching, but that's an important skill to develop, and the overall experience made me appreciate good quality code.
From the stars,
FR.
The final report
Problem
Fix flaky tests in Python with an emphasis on non-order-dependent categories
Summary
Results
- Fixed flakiness for 26 tests across 7 repositories. Opened 8 pull requests, of which 2 got accepted.
- Wrote Python script for aiding in selecting flaky tests to fix.
Other Effort
- 3 PRs got rejected.
- Tried fixing a lot more tests since progress4 but was largely unsuccessful due to a variety of reasons.
Total Effort
(Estimated) 140 - 150 hours. (~50 hours from progress1 to progress3, rest from progress4 to end)
Longer Description:
-
Wrote a Python script to help finding repositories to choose for fixing flaky tests.
- Motivation: A lot of the tests (when chosen arbitrarily from
py-data.csv) were on old repositories that were not maintained). - Script looks at URL from
py-data.csvorpr-data.csvand for each repository, notes down two pieces of information: number of stars, and number of months since last commit to default branch. Also, it only looks at repositories that have atleast one test which has not been fixed. - Script added to IDoFT repo .
- Used this script to help find archived repositories (i.e. likely that archived repos had no commits for a long time), which I updated in
py.data.csv.
- Motivation: A lot of the tests (when chosen arbitrarily from
-
The three pull requests which were rejected was very well documented, but maintainer of repository (same maintainer for all 3 PRs) felt that the situation under which the tests were flaky wouldn't occur in real life. This was the reason why the PR was closed. In my opinion it was not a fault with the PR itself, but the situation under which the fix would be useful.
-
Progress since progress4 was not very good. Only managed to open two PRs.
-
In general, fixing flaky tests in Python was challenging due to the following reasons (not in any order):
- Ran into issues during installing required libraries
- Flaky behaviour not found (either due to failure in re-creating or flaky test got fixed)
- Default tests were failing- no use fixing flakiness when default tests are failing
- Unable to reproduce flakiness. Used three different methods to test for flakiness:
pytest-flakefinder- Preferred method of finding flaky tests.pytest-random-order- Ran tests in random order. Did not use much because developers might argue tests will never be run in any other order than they are written, which means my PR would have a high chance of getting rejected.ipflakies- Execution of this plugin took way too much time even with low number of iterations, was not suitable for quick test running. Thus, did not use plugin much.
- Unable to fix / find source of flakiness- Highest reason why so many tests were explored and not fixed. The packages were complex and in general was very difficult to find source of flakiness.
- Many tests are on repositories that are not maintained, so chance of PR getting accepted on an unmaintained project is very less
- Not many order-dependent tests to fix. These tests are (in my opinion) very easy to fix, but due to the fact that Python tests don't have such issues like in Java (as per my experience), fixing tests in general have been very difficult.
- Existence of flakiness does not warrant a fix. On a good portion of the tests I've seen so far, tests are meant to be run more than once- a lot of tests were very hard to debug and impossible to fix because they dealt with temporary files/directories, objects with persistent memory, etc. Fixing flakiness would require too many lines of code to be changed- developer would likely not agree with so much changes for an issue that isn't going to be a problem (an issue here referring to flakiness not being a problem because tests are always run in the same order / not run more than once.)