A note from Future Faaez from 26th June, 2022: Hey ya'll. Hope you're doing good. I published a paper under Springer on this topic, titled "Predicting Movie Success Using Regression Techniques", in the Intelligent Computing and Applications book, proceedings of ICICA 2019. Very cool. The entire process of writing a research paper taught me a lot. While you cannot access my paper through the actual publication link , I'm going to directly link it here. Feels illegal but hey, I wrote the damn thing. You can read it here .
A few months ago, I finished a machine learning project as a part of my mini project course last semester. I initially faced a lot of difficulties, since this was my first real machine learning project. You see, the whole process of machine learning involves a certain number of steps. Steps that you need to meticulously follow in a certain order so that the entire process is streamlined and efficient.
And that is exactly what I didn't do.
I'll write about everything that happened. It's gonna be long. And interesting. Maybe.
The Problem Statement
My aim was to find out, using machine learning, the eventual box office revenue of a movie. This would benefit production houses with multiple movies and advertising companies to know which movies to focus their budget on, to get the best return of investment. It would also help theatres to know which movies to showcase more if they knew beforehand if it was going to be succesful.
On a side note, as beginner in data science, this project was just not suited to me at all, since there were a lot of problems with the dataset. I wish I could look back and say I learned a lot, but the truth is I don't think I will ever need the information I learnt in the near future, and when I will, I would've forgot what I learnt.
Approach
The first mistake I did. I never learned from a concrete source. All I did was learn from multiple sources like a maniacal autodidact. Now the problem here was that since I was learning from multiple sources, I did not know the difference between inference and prediction. In short, prediction doesn't need Gaussian assumptions of algorithms to be fulfilled. But inference does. Whenever I googled 'linear regression', every website stressed the importance of fulfulling assumptions but no one said it was meant for inference.
Inference here means knowing what features affect prediction results and how exactly they affect them. For example, to do this accurately with linear regression, these assumptions need to be fulfilled:
- The statistical distribution of your dependent variable (revenue in this case) has to be normally distributed. Now this isn't compulsory but many sources stressed it.
- Your residuals should have constant variance, i.e. they should be homoscedastic.
- There should be no multicollinearity between your features.
- The independent variables and dependent variable should have a linear relationship between them.
I chased after these assumptions like Tom chases Jerry. But to no avail. All I cared about was prediction. But I carried out inference. I used correlation heatmaps and the Variance Inflation Factor to mitigate multicollinearity. I conducted Breusch Pagan tests and white tests to test for heteroscedasticity. I looked for hours at the residual scatter plot trying to achieve the holy grail of homoscedasticity but I just couldn't manage to achieve it. I tried a variety of solutions:
- Using weighted regression
- Applying variance stabilizing transformations
- Log-transforming the dependent variable
- Box-Cox transformations
BUT. NONE. OF. THEM. WORKED. :(
As I was also learning at the same time I was doing the project, I wasted a LOT of time. Time I could never get back. Sigh. But on the bright side, I finally did find out what to do. I will forever be grateful to that one redditor who pointed me in the right direction. I quickly got back on track after that. Thank you, stranger.
A Better Approach
Data Integration
I used two datasets from Kaggle. Dataset1 had 45,000 samples and Dataset2 had 5000. I did an inner join on them using the IMDb ID column to combine both datsets. I did this in order to hopefully get a better prediction due to more number of features. Although this isn't a good idea in some cases. If you have a crap-ton of features, the algorithm needs more computer resources for execution, and there is a possibility of multicollinearity affecting prediction. This is the reason why dimensionality reduction techniques exist. Too much of something is not good.
Except money of course.

Preprocessing
Since two datasets were merged, columns like revenue were repeated- one from each dataset. However there were some discrepancies. Turns out the difference between these columns were 43%.
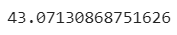
Why was that? After manually googling a randomly sampled movie and checking out its revenue, I found out that one dataset contained global revenue and another contained revenue for the U.S. only. Since I want the scope of the project to be simple, I decided to use the column with U.S. revenue and discard the other.
Next, genre. There were yet again two more the of the same columns. I discarded the column with a lower SPRF (self-proclaimed-relevance-factor), which I define as the average number of genres listed per movie. How this helps in my case I do not yet know. Dataset1 had the genres in an unusual format on which I had to use literal_eval to extract information and extracting the genre from Dataset2 was easy enough, all I used was a split() function. Looking at their individial SPRFs, Dataset2 had more information so I chose to go alone with that and discard the genre column from Dataset1.
This next step contradicts my previous step. I will filter out and use only one genre. While knowing all the genres of a movie might help in building something like a movie recommender system, I do not see the point in using each listed genre of a movie for this project. There was also a feature which listed plot keywords, which would be a massive boon in recommender systems. But then again, that's not the goal here. (I also don't know how to build one). Guess which movie this is referring to:

I then converted the release dates which were objects to a datetime format for convenience.
Converted other columns to a list format which made things simpler:
I then proceeded to drop rows with NA values and then the columns which wouldn't be needed. These wouldn't assist us in prediction for now. Most of these were either repeated columns due to merging of datasets or they were in string formats which I currently do not know how to incorporate as variables. Probably something to do with Natural Language Processing though.
Exploratory Data Analysis
First step was the usual summary statistics. Nothing out of the ordinary. In total, I had 3943 movies to work with, and the summary looked normal.
| belongs_to_collection | vote_average | vote_count | num_critic_for_reviews | duration | director_facebook_likes | actor_3_facebook_likes | actor_1_facebook_likes | revenue | num_voted_users | cast_total_facebook_likes | facenumber_in_poster | num_user_for_reviews | budget | actor_2_facebook_likes | imdb_score | movie_facebook_likes | release_year | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 3943 | 3943 | 3943 | 3940 | 3943 | 3941 | 3936 | 3941 | 3538 | 3943 | 3943 | 3934 | 3942 | 3735 | 3940 | 3943 | 3943 | 3943 |
| mean | 0.232057 | 6.1756 | 843.994 | 155.426 | 109.074 | 808.728 | 754.083 | 7538.62 | 5.53721e+07 | 98324 | 11238.3 | 1.40061 | 317.014 | 3.77482e+07 | 1955.27 | 6.40043 | 8580.47 | 2001.89 |
| std | 0.422199 | 0.923562 | 1375.08 | 123.202 | 22.2028 | 3101.7 | 1841.57 | 15448.4 | 7.14944e+07 | 149379 | 18902 | 2.06644 | 404.701 | 4.3254e+07 | 4437.71 | 1.08069 | 20789.1 | 12.6284 |
| min | 0 | 0 | 0 | 1 | 20 | 0 | 0 | 0 | 162 | 27 | 0 | 0 | 1 | 218 | 0 | 1.6 | 0 | 1929 |
| 25% | 0 | 5.6 | 96 | 65 | 95 | 10 | 203 | 745 | 1.06441e+07 | 15254 | 1963 | 0 | 94 | 9e+06 | 395.75 | 5.8 | 0 | 1998 |
| 50% | 0 | 6.2 | 335 | 125 | 105 | 57 | 434.5 | 1000 | 3.24037e+07 | 46221 | 3924 | 1 | 191 | 2.3e+07 | 680 | 6.5 | 209 | 2005 |
| 75% | 0 | 6.8 | 966 | 212 | 119 | 218 | 690 | 12000 | 7.09471e+07 | 114780 | 15777.5 | 2 | 377.75 | 5e+07 | 969.25 | 7.2 | 10000 | 2010 |
| max | 1 | 10 | 14075 | 813 | 330 | 23000 | 23000 | 640000 | 7.60506e+08 | 1.68976e+06 | 656730 | 43 | 5060 | 3e+08 | 137000 | 9.3 | 349000 | 2016 |
I took a pairplot and I can infer nothing from this except the fact that it looks kinda cool:
Looking at the distribution of the dependent variable, revenue, we can see that it exhibits a Pareto distribution. Right now it's beyond my scope to understand what a Pareto distribution actually is. Though as you can see, the distribution isn't normal. If you take log of the values, you will ensure normality but this made a lot more problems down the line that I wasn't equipped to handle. And as mentioned before, since this is just prediction, normality won't matter.
Next, looking at the barplot of the number of movies released each year, we can see that the bulk of the graph is towards the right. I'll take 1995 as the cutoff year, i.e. only taking movies released after 1995 into account.Why?
- We don't have a lot of movies released before around the 1995 mark.
- The budgets/revenue are not adjusted for inflation over time.
- Movies of the previous century tend to be different than the movies of the 2000s in a lot of ways. For instance, the budget allocated for movies after 2000 would be much more than ones before 2000. Again, inflation probably plays a role here but for simplicity I will not be working with the old movies.
Looking at the overall budgets each year, I could've taken 1990 but it had a few empty values for some months- which I found using a heatmap, so I chose 1995.
| release_year | budget |
|---|---|
| 1991 | 7.8e+08 |
| 1992 | 8.481e+08 |
| 1993 | 8.406e+08 |
| 1994 | 1.50823e+09 |
| 1995 | 2.18842e+09 |
| 1996 | 2.98832e+09 |
| 1997 | 3.767e+09 |
| 1998 | 4.00917e+09 |
| 1999 | 4.85151e+09 |
| 2000 | 5.35919e+09 |
| 2001 | 5.78994e+09 |
| 2002 | 6.24845e+09 |
| 2003 | 5.60795e+09 |
| 2004 | 6.42082e+09 |
| 2005 | 6.91549e+09 |
| 2006 | 6.36845e+09 |
| 2007 | 5.91766e+09 |
| 2008 | 6.89685e+09 |
| 2009 | 7.25924e+09 |
| 2010 | 7.90192e+09 |
| 2011 | 6.75924e+09 |
| 2012 | 7.71880e+09 |
| 2013 | 8.14001e+09 |
| 2014 | 7.58364e+09 |
| 2015 | 7.32028e+09 |
| 2016 | 5.1269e+09 |
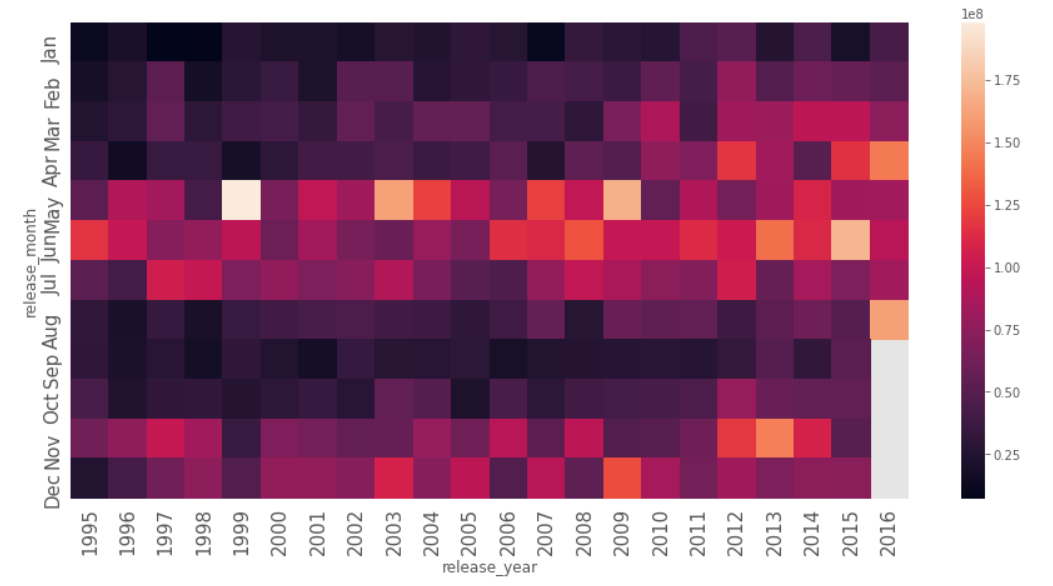
Looking at a heatmap of the revenue over different months of different years, we can see that most revenue is made in the months May, June, July, November, and December.
Feature Engineering
According to the internet:
Feature engineering is the process of transforming raw data into features that better represent the underlying problem to the predictive models, resulting in improved model accuracy on unseen data.
Woo! Exciting! Never tried this before, however I made three very basic features. The model accuracy did improve, however it was by a very small amount. More on that later. The features I engineered were:
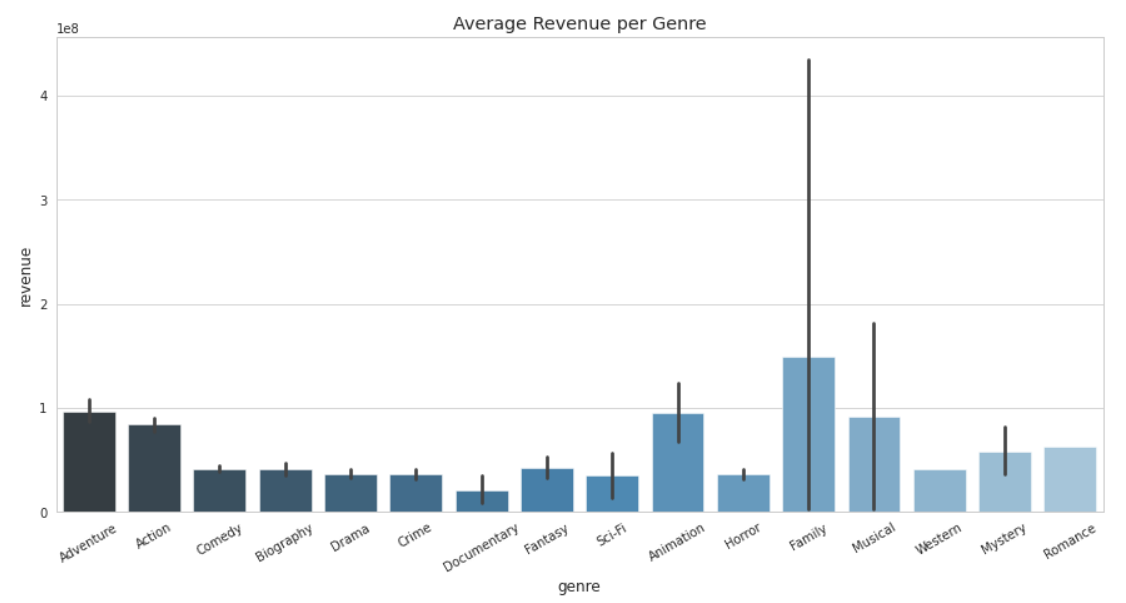
action_or_adventure: The revenue across different genres were studied upon. Upon visual analysis, it was found that Action and Adventure movies on average earned more revenue when compared to other genres. Thus, a new column was created, which contains a 1 if the genre of the movie is either action/adventure, else contains a 0. I'm not statisically sound yet, but I do know that the error bars here represent the level of uncertainty for that particular genre. Taking that into account, we're left with action and adventure genres.
top_director: The top 10 directors sorted in descending order by average revenue per movie were used to create a new column, calledtop_director, which contains a 1 if the director of that particular movie is a top director, else contains a 0.
The top 10 directors are:
| director_name | revenue | |
|---|---|---|
| 0 | Steven Spielberg | 4.11423e+09 |
| 1 | Peter Jackson | 2.58992e+09 |
| 2 | Michael Bay | 2.23124e+09 |
| 3 | Tim Burton | 2.07128e+09 |
| 4 | Sam Raimi | 2.04955e+09 |
| 5 | James Cameron | 1.94813e+09 |
| 6 | Christopher Nolan | 1.81323e+09 |
| 7 | George Lucas | 1.74142e+09 |
| 8 | Joss Whedon | 1.73089e+09 |
| 9 | Robert Zemeckis | 1.61931e+09 |
Steven Spielberg! No surprise there.
Feature Selection
According to the interwebs:
Feature Selection is the process where you automatically or manually select those features which contribute most to your prediction variable or output in which you are interested in. Having irrelevant features in your data can decrease the accuracy of the models and make your model learn based on irrelevant features.
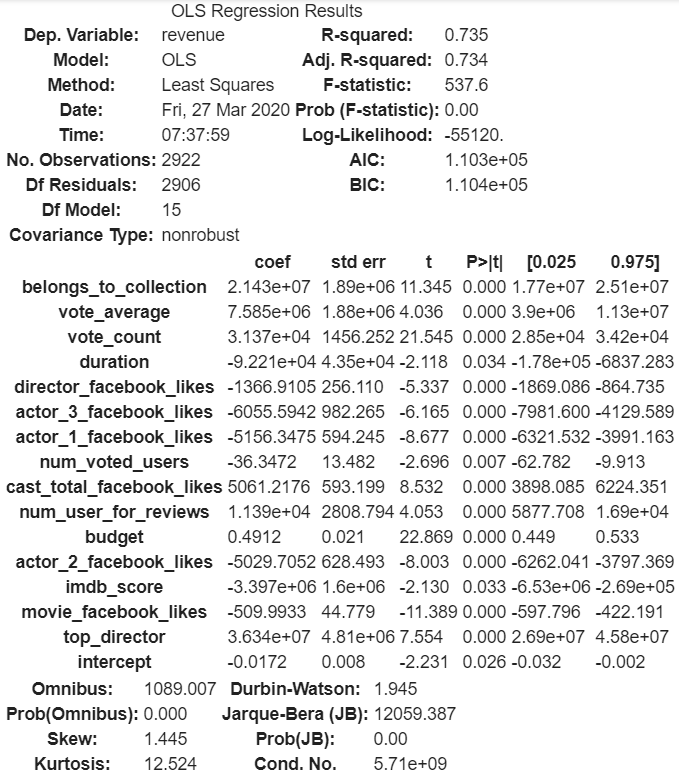
First thing I did for feature selection was to conduct backward elimination. Backward elimination is an iterative process starting with all variables and in each iteration, deleting the variable whose loss gives the most statistically insignificant deterioration of the model fit, and repeating this process until no further variables can be deleted without a statistically significant loss of fit. Here, the probability value (p-value) was used. In simple terms, if the p-value of a certain feature is 0.05, then it means that there is a 5% chance that the results obtained were due to pure chance rather than due to the statistical features of the data. Overall, three features were removed after doing backward elimination 3 times. These feature were facenumber_in_poster, num_critic_for_reviews, and release_year. The backward elimination itself was done using statsmodels OLS, which required that the constant of the linear regression equation be added manually.
Multicollinearity
Multicollinearity is when a feature may be correlated with another feature. For inference, this needs to be removed. Why? If two variables contribute approximately the same to the dependent variable's outcome, it's useless to use both since we cannot measure individual contribution and importance of a single variable. The heatmap below shows that multicollinearity indeed exists but I will not be removing them. As I've mentioned before, I don't care about it when it comes to prediction.

Machine Learning
Finally! The part everyone's been waiting for. Nothing too complicated, just split the datasets into testing and training sets and ran them through a plethora of regression algorithms:
Linear Regression: Multiple linear regression is a technique that uses multiple explanatory variables to predict the outcome of a single response variable through modeling the linear relationship between them. It is represented by the equation below:
Support Vector Regression: A Support Vector Machine is a classifier that aims to find the optimal hyper-plane (the separation line between the data classes with the error threshold value epsilon) by maximizing the margin (the boundary between classes and that which has the most distance between the nearest data point and the hyper-plane). In this project, a linear kernel was used.
Decision Tree Regression: A decision tree is a supervised classification model that predicts by learning de-cision rules from features. It breaks down data into smaller subsets by making a decision based on asking a series of questions (the answers are either True or False), until the model gets confident enough to make a prediction. The end result is a tree, where the leaf nodes are the decisions. The questions asked at each node to determine the split are different for classi-fication and regression. For regression, the algorithm will first pick a value, and split the data into two subsets. For each subset, it calculates the MSE (mean squared error). The tree chooses the value with the smallest MSE value. After training, the algorithm runs it through the tree until it reaches a leaf node. The final prediction is the average of the value of the dependent variable in that leaf node. The usage of a single decision tree gave the worst results. While decision trees are supposed to be robust against collinearity, they did not perform better than linear regression.
Random Forest Regression: Random forest is an ensemble method, which means that it combines predictions from multiple machine learning algorithms, in this case, decision trees. The problem with decision trees is that they are very sensitive to training data and carry a big risk of overfitting. They also tend to find the local optima, as once they have made a decision, they cannot go back. This was evident by the fact that the R2 value and correlation varied in each iteration of running the algorithm. Random forest contains multiple decision trees running in parallel, and in the end, averages the results of multiple predictions. Random forests with 100 trees were found to have the best results among all algorithms used in this project.
Ridge Regression: Ridge regression L2 uses regularization, which is a method used to avoid over-fitting by penalizing high-valued regression coefficients through shrinkage, where extreme values are shrunk towards a certain value. Particularly, In L2 regularization, the coefficients are penalized towards the square of the magnitude of the coefficients. Ridge regression is a technique used to mitigate multicollinearity in linear re-gression. While the fulfillment of the multi-collinearity assumption is not necessary for prediction and is only necessary for inference, using Ridge Regression decreased performance. The cause of this was not clear.
Lasso Regression: Similar to ridge regression, lasso regression shrinks all coefficients towards a value, in this case, the absolute value of the magnitude of coefficients. This is called L1 regularization, and can sometimes lead to elimination of some coeffi-cients. Lasso regression had similar performance to Ridge regression.
The metrics used to measure the efficacy of these algorithms were:
- Mean Absolute Error
- Mean Squared Error
- Root Mean Squared Error
- R2 (coefficient of determination)
Results
| Algorithm | Correlation | MAE | MSE | RMSE | R2 | |
|---|---|---|---|---|---|---|
| 0 | Linear Regression | 0.846941 | 0.0328154 | 0.0026032 | 0.0510215 | 0.70225 |
| 1 | Support Vector | 0.837982 | 0.0431082 | 0.00322953 | 0.238237 | 0.644978 |
| 2 | Decision Tree | 0.748082 | 0.0431082 | 0.00322953 | 0.238237 | 0.644978 |
| 3 | Random Forest | 0.885413 | 0.0320000 | 0.00250000 | 0.050000 | 0.712100 |
| 4 | Ridge | 0.855921 | 0.0431082 | 0.00322953 | 0.238237 | 0.644978 |
| 5 | Lasso | 0.860000 | 0.0431082 | 0.00322953 | 0.238237 | 0.644978 |
Not immediately clear which algorithm performs better. By visually representing them, we can see it better. Since correlation and R2 are on different scales, I will seperate them from the rest of the metrics.
Looking at the results above, we can see that Random Forest had the best performance out of all the algorithms. The next best algorithm was linear regression, due to it's low error scores.
The Most Important Features
While looking at different blogs on the internet, I came upon something called feature_importances, which basically means the features most responsible for determining the revenue of a movie. This was done using Random Forest Regressor. In each individual tree in the forest, the decision is made based on the MSE (Mean Squared Error). When training individual trees, the degree of how each feature decreases the MSE can be averaged. The features are then ranked accordingly in ascending order.
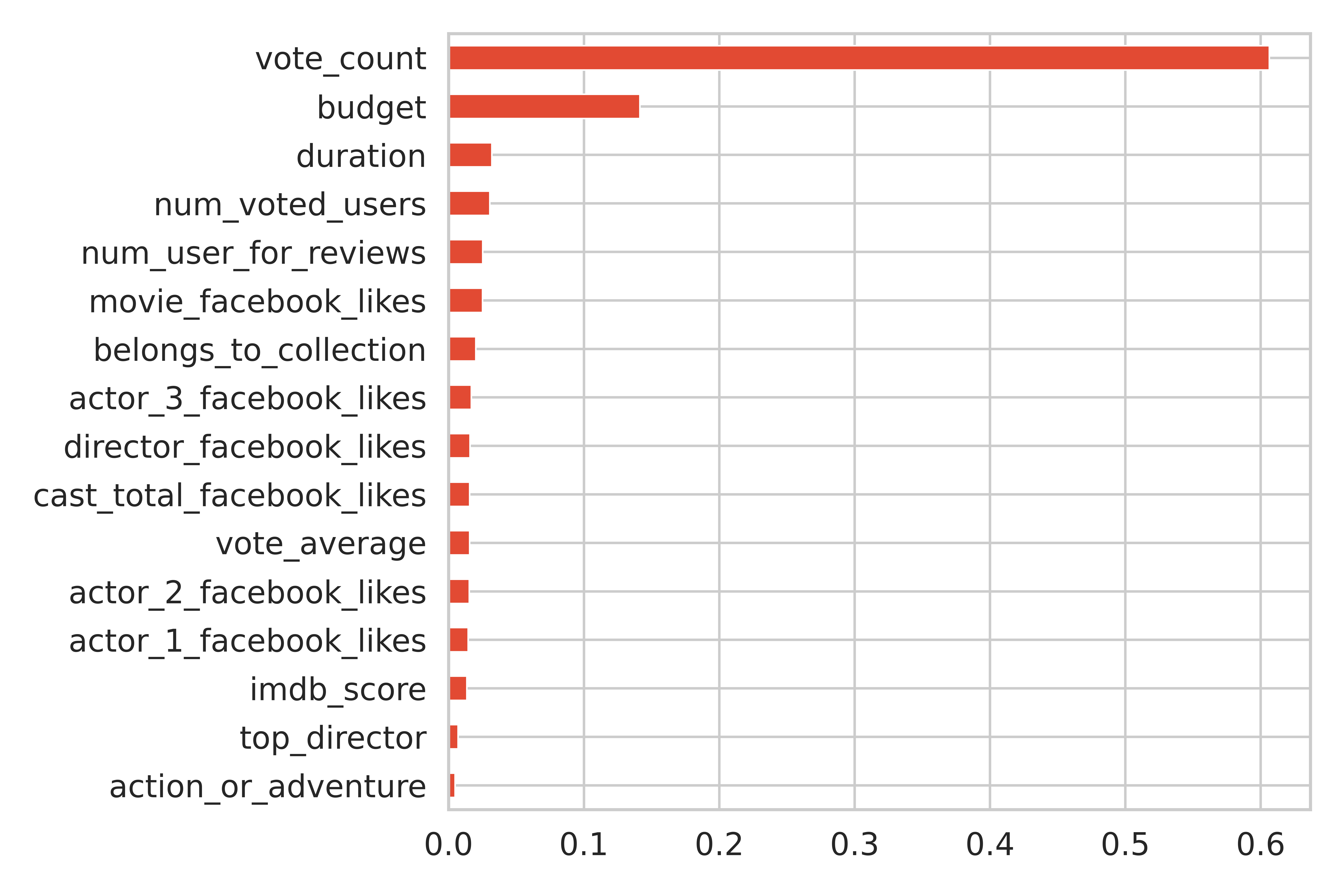
According to this, the number of votes garnered online and the budget allocated for a movie were the most important in determining the overall revenue of a movie.
Final Thoughts
Phew! My first ever full fledged machine learning project. Went kinda good, except for the statistical roadblocks, and the lack of a path. Guess this is what machine learning projects are all about- you need to have statistical knowledge, and a concrete sequential way of doing things. I have a lot of studying to do. I'm almost sure that somewhere in my code I've messed up (statistically, that is) which causes my results to be inaccurate. Well. That's something to worry about in the future.
From the stars,
FR.