Bash Scripting for Automated AWS S3 Downloads
- 9 min read
- AWS
- Bash
- Linux
- Data Warehousing
6 years ago
The company I'm currently interning at was planning to set up an on-premise datawarehouse. Usually, this it too expensive so many companies shift to Amazon Redshift for their data warehousing needs. But we had the hardware set up and ready. Usually, there would be people accessing the warehouse for different needs.One such group of people worked with .csv files that arrived on a daily basis. They wasted extra time on ETLing everything so I was tasked with implementing a possible time saving alternative. I had to set up a pseudo data lake in which these files would be stored. For those who don't know what a data lake is:
A data lake is a system or repository of data stored in its natural/raw format, usually object blobs or files. A data lake is usually a single store of all enterprise data including raw copies of source system data and transformed data used for tasks such as reporting, visualization, advanced analytics and machine learning. A data lake can include structured data from relational databases (rows and columns), semi-structured data (CSV, logs, XML, JSON), unstructured data (emails, documents, PDFs) and binary data (images, audio, video).
For my purposes, the data inside this lake would limited to .csv files. Files would come in on a daily basis and be stored in the lake. The on-premise data warehouse needs to take only the new files and upload them to its warehouse, on a timely basis. For the proof of concept, I was told to implement the warehouse using Clickhouse , which is a columnar-oriented database system. For those who don't know, a columnar format like ORC or Parquet is much, much more efficient than row based formats like .csv. It's a godsend if you're working on the AWS ecosystem, because you get to save on both time and money. How you ask? In a simple sense, AWS charges you for both storage and query execution time. Since formats like Parquet take up much less space and are more efficient, you end up saving a lot of money in the long run. This comparison shows how amazing columnar-oriented file formats are:

As cool as columnar-oriented files are, I did not use them for my proof of concept. Simply because I was just learning the AWS ropes and had no need for them except knowing that they existed. However this could be easily achieved using AWS Glue , which an ETL service. You could easily set up and AWS Lambda trigger which would be invoked each time a new file is uploaded. This Lambda function would then convert the .csv files to Parquet files and store them in a separate S3 bucket.
ETL is short for extract, transform, load, three database functions that are combined into one tool to pull data out of one database and place it into another database. Extract is the process of reading data from a database.
Woah! This blog is about bash scripting. Why am I talking about all of this? Because Clickhouse isn't available for Windows. And what is bash script anyways? In very simple terms, it's just a file containing a bunch of bash commands that you can run sequentially. I had access to an OpenStack Linux instance running CentOS 7. Pretty cool. All I had to do was SSH in and boom! Linux. It was kinda unnerving to interact with an OS using the terminal alone, but pretty soon I came to love it. Not more than GUIs mind you, but it has a special charm of its own.
Anyway.
This is how I envisioned my script would work:
- Check if new files have been added on S3 using AWS CLI.
- If no, download all files with .csv extension using
aws sync. - If yes, get list of new files by doing comparison between local list of downloaded files and list of all files on S3.
- Download new files using
aws cp.
Onwards!
The Script
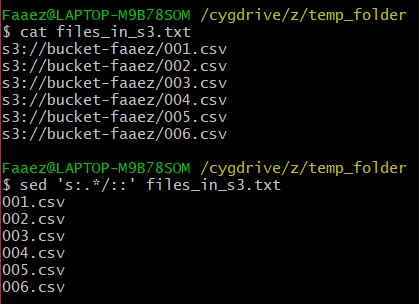
First step is to check if there are files to download. I do this by listing all files in my S3 bucket and storing the output to a text file.
Now, the files are listed with their full file paths, i.e with the name of the bucket and the folder they are in. We don't want this, we only want the names of the .csv files. So I use sed which is stream editor. It allows us to easily manipulate files using regexes. All I wanted was the name of the files, so I used a regex which would remove all text before the '/'. This unfortunately caused some empty lines to appear, which again can e removed using stream editor.
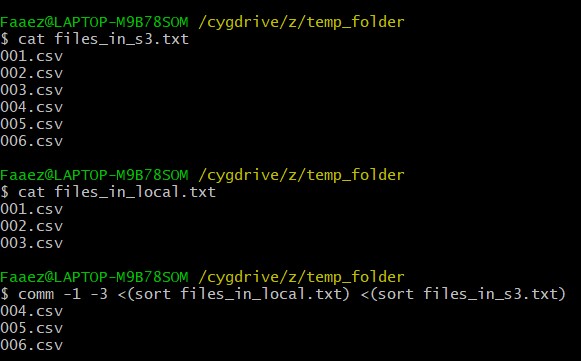
Now's the interesting part. Remember I said that the warehouse only needs to downloaded the new files? Well here's how we do it. I keep a local text files containing the names of all the files that have been downloaded so far. Initially, this file would be empty. Then using the list of all files from S3, we perform a set difference between the files to get the files that we need to download. For those of you who are hazy on set theory, A-B basically says to take elements existing in A but not in B. So basically, all the new files.
We can do this using the comm command, which stands for common. It requires that the files be sorted, so we have to sort them beforehand. The -1 argument removes lines unique to the first file (passed as the first argument) and -3 removes lines that appear in both files. So what we're left with is the files left in the second file. The output of this is the saved to another text files, using > which is the redirection operator. Basically redirects your output to another place. On another hand, so many text files!
Next, we need to check if our local database is already up to date. This is easy, as we have to check if the files_to_download.txt is empty or not. If it is, we exit the script. Else, we move on. I iterate through each name in the text file and pass them to the aws cp command, with the --quiet option, so that my script's output looks clean.
The next step is to upload these files to our Clickhouse database. The tables have already been created beforehand, with the necessary types. Unfortunately there is no way to do this dynamically, as Clickhouse is relational, as many other databases out there. Once we create our tables before hand, we upload them using clickhouse-client. Additionally, we don't have further need for those downloaded .csv files, so we remove them too. And in the end, we remove all text files except files_in_local.txt.
The s | grep XYZ > file_checker.txt line is necessary because there were two different .csv files coming in, each with their own different names appended to the end. Let's say those two different files had "ABC" and "XYZ" and the end of their names. Since they're both different, they needed to be uploaded into different tables. We can filter them out using grep , which is one of my favourite commands. It stands for *globally search a regular expression and print.* Basically, search for files which match a certain search criteria which you specify using regex.
Linux Life Hack: If you can't remember the a command you typed before, just do history | grep <key> where key is any word in that command. You'll be presented with your command history and can easily find out the exact commands you executed before. You're welcome.
And We're Done!
Except we're not. Once I built my solution, I went and asked if it's alright. They said no, the main reason being that I'm storing the names of these files in a plaintext format. They stated that flat files are prone to corruption, and it'll be nasty if the file size grows too long. My solution does not hold up against scale. I also found some other reasons why it wouldn't be good:
- as the text file grows, searching it becomes slow.
- using
commrequires us to sort both files, which would eventually cause a bottleneck. aws lscan only list a maximum of 1000 files, so my solution wouldn't work if there were more than a 1000 files.
In hindsight, I should've thought about this. Listing every single file on the S3 bucket each time it had to update the database seemed wasteful. Moreoever, the bucket would only grow about 2 files per day. At a certain point down the line, it would hinder efficiency. This solution, as I stated before, would not be scalable if there were other types of files coming in.
Nevertheless, this was a good introduction to the world of shell scripting. Can I do this again from scratch? Heck no. Thank you Google, and thank you all for reading this blog post. See you later. And here's the entire script in case you'd want to see it. Why would you want to see it??
From the stars,
Faaez.